







Automatic Speech Recognition 101: How ASR systems work

Speech Recognition Engineer

Tags
Share
Giving our customers the benefits of AI to help them have smarter calls and meetings is a big part of what motivates Dialpad. We believe in a future where you are freed from taking notes to focus on the conversation itself, letting you deliver a better customer or business experience.
But before Dialpad Ai analyzes the conversation and finds answers to tough questions, how does it do the note-taking for you? If you want to know the answer to that question, follow along!
In this post, I’ll walk you through the basics of the first and crucial step of Dialpad Ai: automatic speech recognition.
What is (ASR) automatic speech recognition?
The goal of automatic speech recognition, or simply ASR, is to transform a sequence of sound waves into a string of letters or words. This is what results in the transcript.
Only after we’ve transcribed the audio can we add additional features like Real-time Assist (RTA) cards...
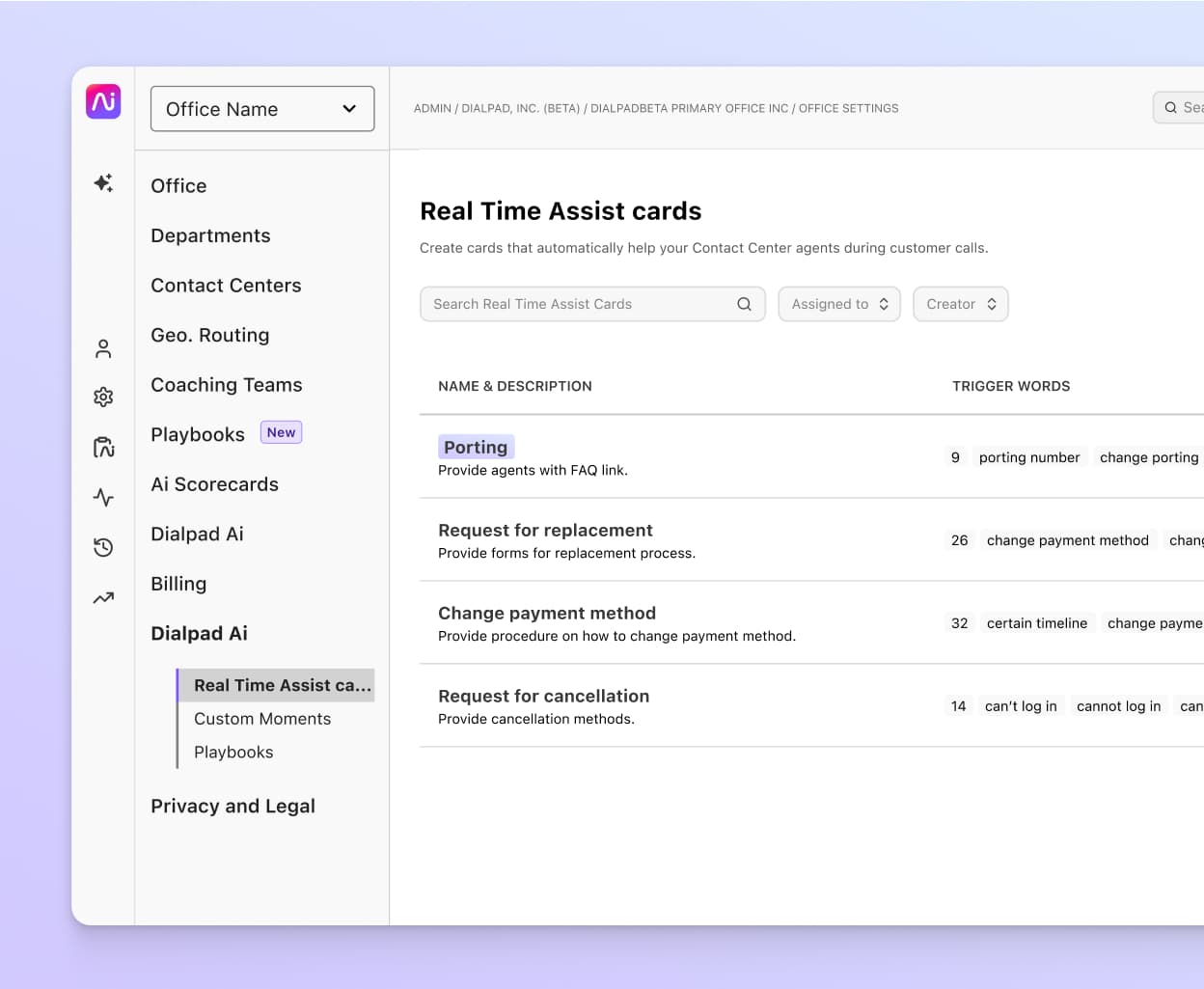
And sentiment analysis, which automatically tells a contact center manager if any of their agents' calls are going south:
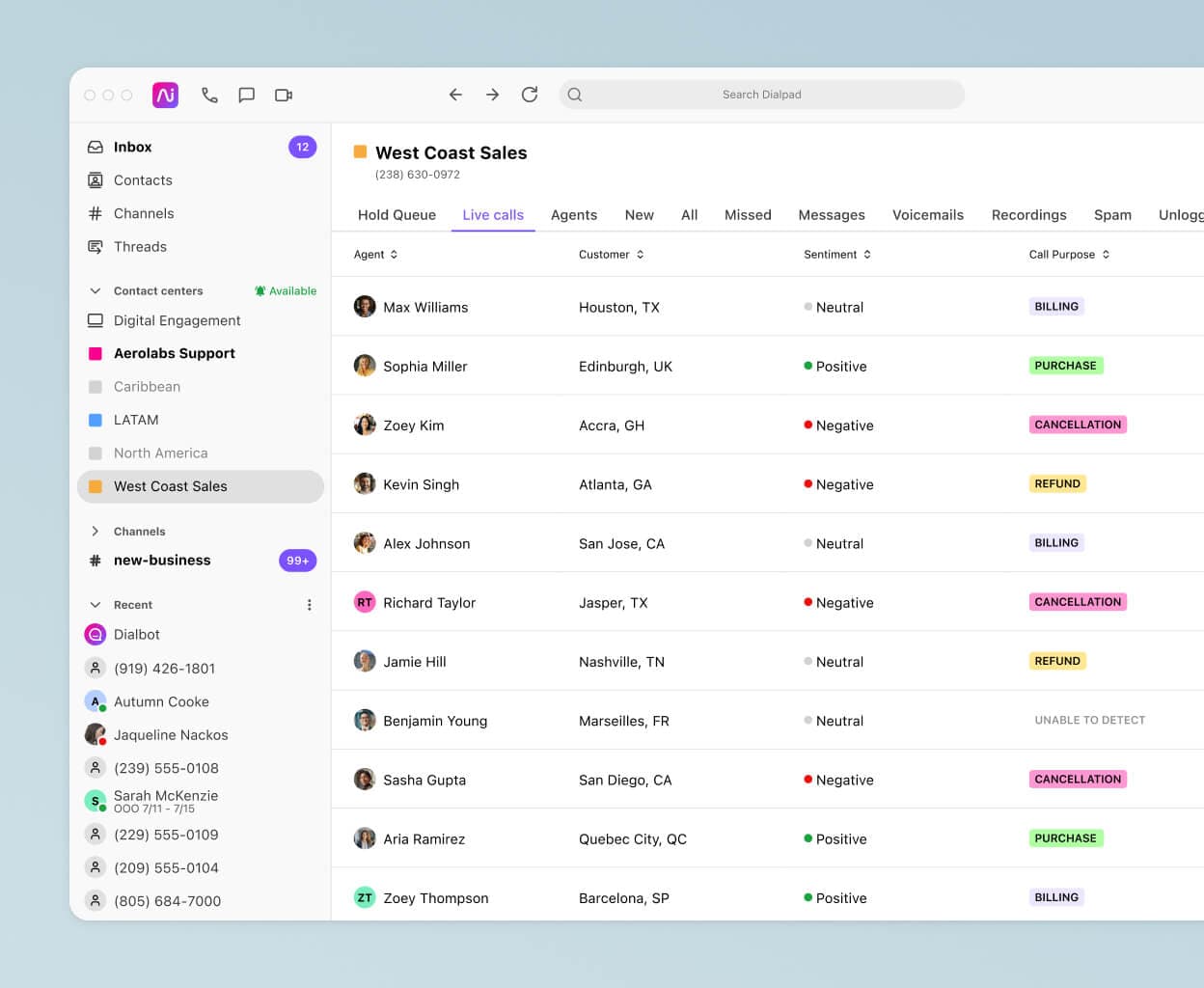
Both of these handy features require our platform to analyze the content of the transcript, and the accuracy of those features depends on the quality of the input transcript.
This is why it’s so important to achieve high accuracy in ASR.
ASR is not only the first step of the two-step process when you want to transcribe conversations in real time, but also arguably the harder one. (The second step is text processing, which isn't quite as complicated because speech recognition deals with way more variability in language.)
For example, there are structures and vocabularies in spoken language that are uncommon in written language, like “disfluencies” (stuttering and hesitations) and filler words. Not only that, there are innumerable different dialects, and people’s voices can vary wildly in how they sound.
An ASR model or automatic speech recognition software has to be able to generalize across all these differences and learn to focus on the aspects of the speech signal that actually convey information about the words spoken, while filtering out those which do not.
Plus, spoken language has other variables that speakers commonly take for granted in everyday use. As an example, let’s consider the phrases “the dogs’ park” and “the dog Spark.”
Same set of letters, in the same order. But when you say them out loud, the “s” in the former sounds more like “z,” while the “p” in the latter sounds more like b. They also convey different meanings along with this subtle sound change.
When our (or any) ASR system converts speech to text, it also needs to pay attention to these subtle differences in speech sounds and disambiguate what is being said (basically meaning to tell which one is the right interpretation).
📚 Further reading:
Learn more about AI transcription accuracy and why it can be difficult to achieve.
Different ways of training automatic speech recognition systems
The two main types of ASR software variants are directed dialogue conversations and natural language conversations—and they're trained in different ways. Let’s take a closer look at them.
Directed dialogue conversations
Directed dialogue conversations are a simple version of ASR in which the system is programmed to steer conversations in a certain direction. It does this by instructing callers to respond with a specific word or phrase from a limited list of options, such as: “Do you want to pay a bill, check your account, or speak to an agent?” This type of ASR system is only capable of processing these directed responses.
The system is trained by human programmers, who manually go through conversation logs for a particular software interface and identify commonly used words that are not yet listed in the system’s vocabulary. Those words are then added to the software, to help it understand a wider range of responses. This method is called tuning.
Natural language conversations
Natural language conversations are about combining automatic speech recognition and understanding, using natural language processing (NLP) technology. This allows for a more advanced version of ASR, which can simulate a “real” open-ended conversation. the system might say “How can I help?” and would be able to interpret a wide variety of responses instead of a limited menu.
Advanced examples of these systems are Siri and Alexa. They are trained using a method called active learning, where the software itself is programmed to autonomously learn and adopt new words. By storing data from previous interactions, it constantly expands its vocabulary. The typical vocabulary of an NLP ASR system consists of around 60,000 words.
Through end-to-end deep learning, ASR can be trained to recognize dialects, accents, and industry jargon. It can also distinguish between different voices, which is super-handy for Dialpad’s real-time transcripts of conference calls and video meetings.
📚 Further reading:
Learn more about NLP in customer service.
How does automatic speech recognition work?
As someone who loves learning languages, I find a lot of parallels between how people learn a new language and how our ASR system learns to recognize speech. Let’s say you want to start learning a new language as an adult, the traditional way is to buy a textbook, or go to a formal language course.
If you sign up for a course for that language, you'd probably need to buy a few books: one that explains how to say the sounds represented by the letters, a dictionary that shows how to pronounce each word, and a grammar book that shows how to form sentences. (There are also textbooks that serve the function of all three, and more!)
The teacher might go through these books in a sequence of lessons. You first learn the smallest units in a spoken language which are called phonemes in linguistics. For example, think of how a child is taught to "sound out" words by making noises for each individual letter in a word. You also learn how to combine phonemes into words.
You’ll then learn the vocabulary and grammar rules. Finally, through listening and reading, you encounter examples of the target language, reinforcing the rules you learned about the language. Through speaking and writing, you apply those rules and get feedback on whether our generalization of the rules is correct.
Gradually you’ll build connections between the different layers of abstractions (shown in Figure 1), from sound, to phonemes, then to words, and finally sentences, until you can do any conversion between these layers in an instant.

This is how we recognize speech in a second (or third!) language that we learn through language courses.
It’s also the theoretical foundation behind the most common ASR method—we guide the ASR system with linguistic concepts such as phonemes, words and grammar, dividing the system into modules to handle different components: the acoustic model, the pronunciation dictionary (AKA the lexicon), as well as the language model.
Each of these components models a step in the sequence of transforming the original audio signal into successively more interpretable forms, as shown in Fig 1 and Fig 2. Here's a quick overview of how it works:
After converting the data from soundwaves to a sequence of numbers that can be understood by computers, we use the acoustic model to map the string of acoustic features to phonemes, then...
The lexicon maps the phonemes to actual words, then...
Our language model predicts the most probable word sequence:

An "end-to-end" approach to ASR
There is, however, also an alternative method for ASR: an “end-to-end” approach that's been gaining popularity.
As opposed to the traditional classroom language class, you may have heard about “immersion” language programs where you just talk to native speakers, and don’t need to sit through (as many) boring grammar lessons. This method has the same appeal.
As the name suggests, in this approach we expect the system to learn to predict text from speech sounds directly. But, as we believe that human language follows a hierarchical structure in Fig 1, we typically still divide the system into two parts:
The first part, called the encoder, creates a summary of the raw audio that focuses on the acoustic characteristics that are most important for distinguishing various speech sounds.
Then we need a decoder that converts the summarized audio to characters directly (see Fig 3). This process is like children learning their first language. They have no preconceptions of vowels, consonants or grammar, so they are free to choose any sort of representation that they see fit, given the large amount of speech they hear every day.
There’s no need for a lexicon, since this model outputs letters, not words, and even newly created words can be transcribed. But since we don’t provide any information about the structure of speech or language, it has to learn it by itself, which takes more time and computing resources. Just as a child takes a few years to start conversing in full sentences...

But no matter which approach we use, in order to build a successful ASR system, we need training data. A lot of data.
It’s just like how we need immersion and practice when we humans learn languages. Here at Dialpad, we use past calls (with our customers’ permission of course) transcribed by humans, to improve our ASR.
Usually, hundreds, if not thousands, of hours of speech data is needed for an ASR system to learn well. We’re hard at work to include more diverse and high accuracy data in order to improve our voice transcription experience!
How we use conversational context to make our transcriptions accurate
I might have made it sound like the ASR system makes the conversion from speech sounds to text with total confidence, like there is a one-to-one mapping between the two. But of course, given one set of speech sounds, there is often more than one way to interpret it.
Even for humans, there are sounds that are similar enough that we can only tell them apart given a specific context. Because of this, a big part of speech recognition is disambiguation. In fact, regardless of the architecture of the ASR system, it’ll provide not just one, but multiple hypotheses of word sequences given one audio input.
The possibilities are stored in what is called a “lattice”: a flow chart of possible sequences (see Fig 4 below).
Each link on the lattice is given a score. For the hybrid approach, this score is the combined output of the three modules. On the other hand, for the end-to-end approach, this is given by the decoder.
What you end up seeing in your transcript is the complete path through the lattice that has the highest total score:

In a real-time scenario, as is the case with Dialpad’s AI transcription, the lattice is constantly changing, and the ASR system is constantly updating scores based on the latest contextual information.
👉 Fun fact:
Have you ever experienced when you didn’t catch what someone said and said, “Pardon,” but before the person says it again, you realize you’ve now understood what was said? That’s probably your brain trying to calculate the score of different sentences just like the machine!
Made it this far? You’ve passed the automatic speech recognition tutorial!
There you have it, the basics of a speech recognition system!
We talked about how automatic speech recognition systems are in fact very similar to how you and I learn and understand languages.
If you want to learn more about Dialpad Ai, or how you can leverage it in your business, check out this post about how Dialpad Ai was built. (And stay tuned for more posts about our advances in AI!)
Never want to take notes again?
See how Dialpad's automatic speech recognition can help you transcribe customer calls more accurately than all competitors out there. Book a demo, or take a self-guided interactive tour of the app on your own!